
Simplifying Database Access in Spring Boot: JdbcTemplate and Spring Data Repositories
When building a Spring Boot app, connecting to a database is often essential. JdbcTemplate and Spring Data are effective options for managing database interactions. JdbcTemplate is a lower-level tool for relational databases, allowing you to write SQL queries directly in Java and requiring a DataSource that Spring Boot can configure automatically.
Spring Data simplifies database interactions by enabling you to work with Java objects instead of writing database queries. It provides various modules for different database technologies, whether relational or NoSQL. You define repository interfaces, and Spring Data automatically generates implementations based on your method names, allowing you to save, find, and delete records without writing complex queries.
JdbcTemplate is part of the core Spring Framework, a project that provides fundamental features like dependency injection, AOP, etc. for building Java applications. In contrast, Spring Data is a separate project focused on simplifying database access across various data storage technologies. Importantly, Spring Data is not a single module but includes multiple modules tailored to different database technologies.
Part 1: Connecting to Databases in Spring Boot with JdbcTemplate
We’ll begin with an in-memory database (H2) to simplify the setup. In-memory databases are excellent for quick testing because they require no installation.
Step 1: Adding Required Dependencies
To use H2, add the following dependency to your pom.xml:
<dependency>
<groupId>com.h2database</groupId>
<artifactId>h2</artifactId>
<scope>runtime</scope>
</dependency>Using <scope>runtime</scope> means that the H2 dependency is needed only when your application is running, not during compilation.
Next, include the spring-boot-starter-jdbc dependency:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jdbc</artifactId>
</dependency>The spring-boot-starter-jdbc dependency is essential for connecting to and interacting with a relational database using JDBC. By adding it to the pom.xml, we automatically get JdbcTemplate and all JDBC capabilities. It simplifies connection management and SQL execution, allowing you to perform database operations like querying and updating without dealing with low-level details.
Step 2: Configure the Data Source
A data source manages and reuses connections to improve app performance by pooling them. This prevents the need to open a new connection with each request. Spring Boot uses HikariCP as the default DataSource, which is fast and easy to configure.
Option 1: Setting Up HikariCP in application.yml
You can configure HikariCP with H2 in-memory database settings directly in application.yml:
spring:
datasource:
url: jdbc:h2:mem:testdb # Change this URL for other databases
username: sa
password: password # Set a password or leave it blank for default
driver-class-name: org.h2.Driver
h2:
console:
enabled: trueThe driver-class-name property specifies the class name of the JDBC driver for your relational database. A JDBC driver is a software component that helps your application communicate with a specific database by converting Java calls into commands that the database understands. Since each database requires a different driver, it’s important to select the correct one for your setup. For example, if you use PostgreSQL instead of H2, you would set this property to org.postgresql.Driver.
Enabling the H2 console allows you to access a web-based interface for managing your in-memory database, making it easier to view and manipulate test data. We’ll see this in a bit.
Note: You don’t need to include a separate JDBC driver for H2 because it is bundled with the H2 database dependency you added to your pom.xml. However, if you decide to use PostgreSQL, you will need to add the appropriate JDBC driver separately.
Option 2: Custom DataSource Bean
Alternatively, you can configure the DataSource programmatically in a configuration class:
@Bean
public DataSource dataSource() {
HikariDataSource dataSource = new HikariDataSource();
dataSource.setJdbcUrl("jdbc:h2:mem:testdb");
dataSource.setUsername("sa");
dataSource.setPassword("password");
return dataSource;
}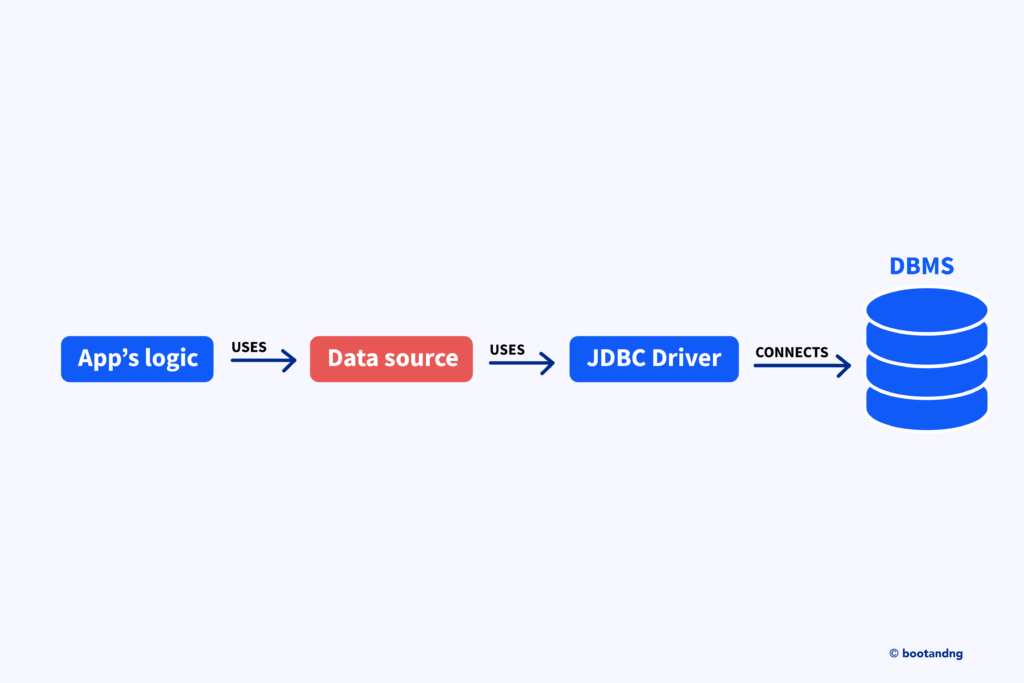
In this setup, your app connects to HikariCP, which acts as the DataSource. HikariCP uses the H2 JDBC driver (org.h2.Driver) to communicate with the H2 in-memory database. The in-memory database temporarily stores data while the application runs, meaning data will be cleared once the application stops.
Step 3: Defining the Database Schema
Spring Boot can automatically execute a schema.sql file to set up the database structure when the app starts. By including the spring-boot-starter-jdbc dependency earlier, Spring Boot gains the necessary JDBC support to load and run these SQL scripts. If a data.sql file exists in the same location, it will also be executed to populate the database with initial data.
To create these files, place a schema.sql file in the src/main/resources folder to define your tables, and include a data.sql file to insert records into those tables.
Example: Creating a schema.sql file:
CREATE TABLE customer (
id INT AUTO_INCREMENT PRIMARY KEY,
first_name VARCHAR(100) NOT NULL,
last_name VARCHAR(100) NOT NULL,
email VARCHAR(255) UNIQUE NOT NULL
);This example creates a customer table with columns for the customer’s first name, last name, and email address, ensuring each email is unique.
Example: Creating a data.sql file:
INSERT INTO customer (first_name, last_name, email) VALUES ('John', 'Doe', '[email protected]');
INSERT INTO customer (first_name, last_name, email) VALUES ('Jane', 'Smith', '[email protected]');In this example, the data.sql file inserts initial records into the customer table. You can add multiple table definitions to the schema.sql file and initial data inserts to the data.sql file to set up your database structure and contents as needed.
Step 4: Building CRUD Functionality with JdbcTemplate
We’ll create a simple system to manage customer data using JdbcTemplate in Spring Boot. This will involve a Customer entity, a repository for database operations such as saving and deleting records, a service layer for business logic, and a controller to handle RESTful endpoints.
First, we will define a Customer entity to represent our customer information. This class will store key details about each customer, including their ID, first name, last name, and email address.
public class Customer {
private int id;
private String firstName;
private String lastName;
private String email;
// Constructors, getters, and setters
}This class organizes customer information for our application.
Next, we’ll create the CustomerRepository, responsible for executing database actions using JdbcTemplate:
@Repository
public class CustomerRepository {
@Autowired
private JdbcTemplate jdbcTemplate;
public void save(Customer customer) {
jdbcTemplate.update("INSERT INTO customer (first_name, last_name, email) VALUES (?, ?, ?)",
customer.getFirstName(), customer.getLastName(), customer.getEmail());
}
public void update(int id, String newEmail) {
jdbcTemplate.update("UPDATE customer SET email = ? WHERE id = ?", newEmail, id);
}
public void delete(int id) {
jdbcTemplate.update("DELETE FROM customer WHERE id = ?", id);
}
public Customer findById(int id) {
return jdbcTemplate.queryForObject(
"SELECT * FROM customer WHERE id = ?",
(rs, rowNum) -> new Customer(rs.getInt("id"), rs.getString("first_name"),
rs.getString("last_name"), rs.getString("email")), id);
}
}By using the spring-boot-starter-jdbc dependency, Spring Boot automatically sets up a JdbcTemplate instance that we can utilize in our repository. This repository makes it easier to work with the database by directly handling SQL queries.
Now, we’ll implement the CustomerService to provide business logic:
@Service
public class CustomerService {
@Autowired
private CustomerRepository customerRepository;
public Customer getCustomerById(int id) {
return customerRepository.findById(id);
}
public String addCustomer(Customer customer) {
customerRepository.save(customer);
return "Customer added successfully";
}
public String updateCustomer(int id, String newEmail) {
customerRepository.update(id, newEmail);
return "Customer updated successfully";
}
public String deleteCustomer(int id) {
customerRepository.delete(id);
return "Customer deleted successfully";
}
}This service layer abstracts the database logic, making it easier to interact with customer data.
Finally, let’s create the CustomerController to expose RESTful endpoints:
@RestController
@RequestMapping("/customers")
public class CustomerController {
@Autowired
private CustomerService customerService;
@GetMapping("/{id}")
public ResponseEntity<Customer> getCustomer(@PathVariable int id) {
return ResponseEntity.ok(customerService.getCustomerById(id));
}
@PostMapping
public ResponseEntity<String> addCustomer(@RequestBody Customer newCustomer) {
String message = customerService.addCustomer(newCustomer);
return ResponseEntity.status(HttpStatus.CREATED).body(message);
}
@PutMapping("/{id}")
public ResponseEntity<String> updateCustomer(@PathVariable int id, @RequestBody String newEmail) {
String message = customerService.updateCustomer(id, newEmail);
return ResponseEntity.ok(message);
}
@DeleteMapping("/{id}")
public ResponseEntity<String> deleteCustomer(@PathVariable int id) {
String message = customerService.deleteCustomer(id);
return ResponseEntity.ok(message);
}
}This controller enables clients to interact with customer data through standard HTTP requests.
Step 5: Testing the H2 Console
To test our changes, we can use the H2 console. First, use Postman to add a random user:
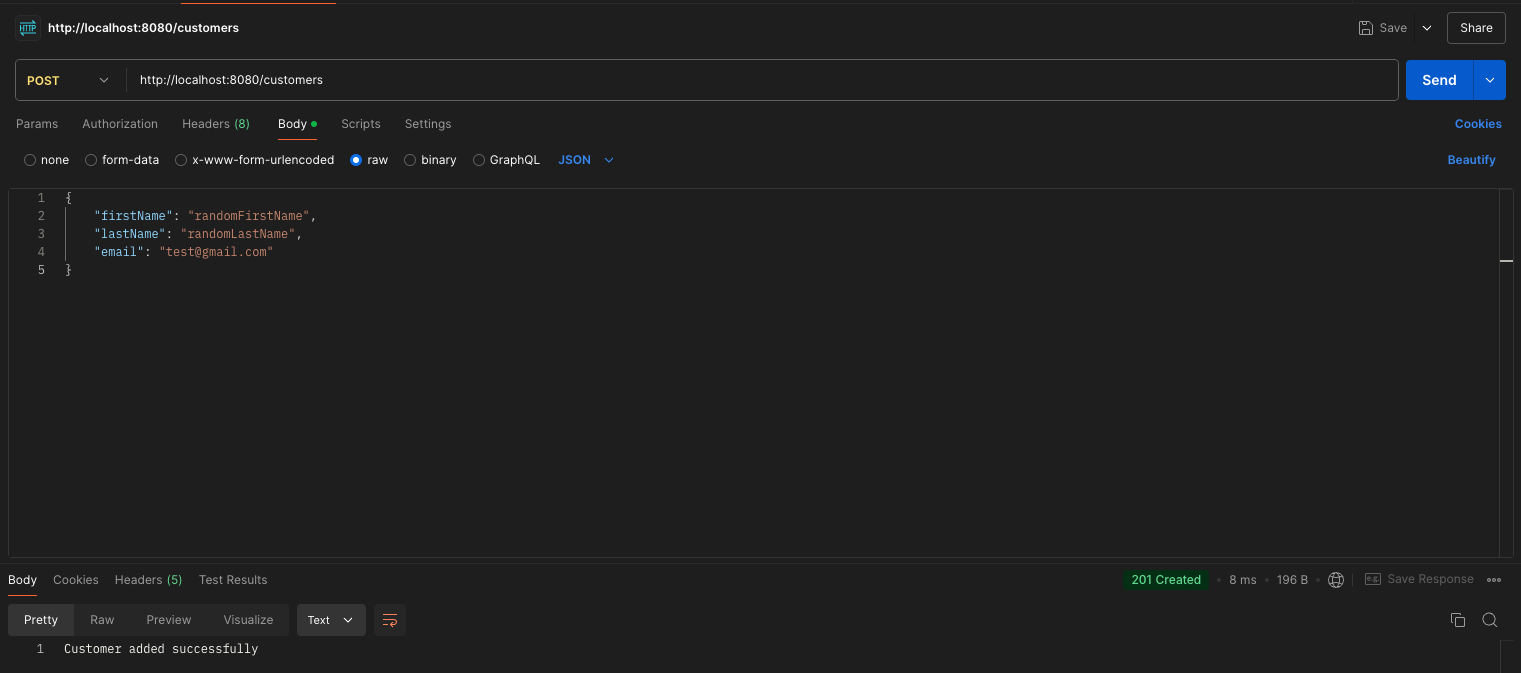
Next, access the H2 console by navigating to http://localhost:8080/h2-console in your web browser. You’ll need to enter the JDBC URL, username, and password configured earlier. After logging in, enter a query to view your database entries.
Part 2: Simplifying Database Access with Spring Data Repositories
While JdbcTemplate is effective for direct SQL interactions, it often requires you to write similar code for common operations across different entities. For instance, if you have multiple entities like Customer, Order, and Product, you would need to create separate repository classes for each one. Each class would require its own methods for CRUD operations, which would follow the same pattern but involve different SQL queries. This leads to a lot of repetitive code, resulting in boilerplate code that makes your application harder to maintain.
Spring Data simplifies this process by allowing you to work with Java objects and automatically generating the necessary database queries. With minimal configuration, you can define repository interfaces that handle common operations across various entities, leveraging built-in support for different relational and NoSQL databases. This approach reduces complexity and improves the readability and maintainability of your persistence layer.
Repository Interfaces in Spring Data
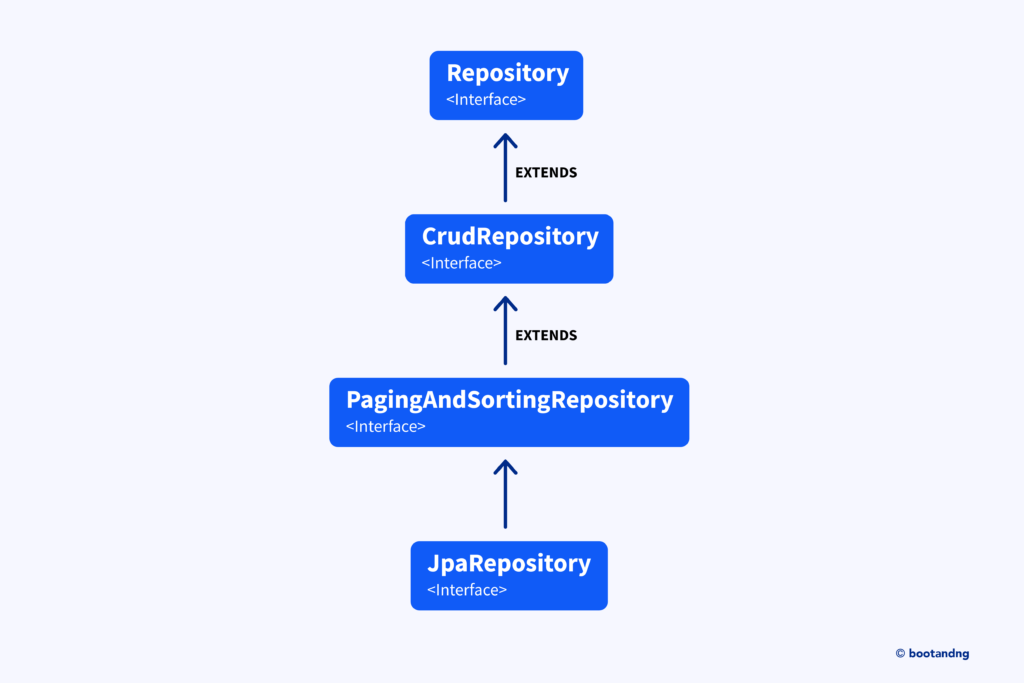
- Repository
The simplest base interface,Repository, serves as a marker with no methods. It represents the top of the contract hierarchy in Spring Data, but it is rarely extended directly. - CrudRepository
If your app needs basic create, read, update, and delete (CRUD) functionality,CrudRepositoryprovides these standard operations.
Example: Defining a repository usingCrudRepository
public interface CustomerRepository extends CrudRepository<Customer, Integer> {
// No additional methods needed for basic CRUD operations
}- PagingAndSortingRepository
If you need to add pagination and sorting to your CRUD operations,PagingAndSortingRepositorybuilds on CrudRepository to provide these capabilities.
Example: ExtendingPagingAndSortingRepository
public interface CustomerRepository extends PagingAndSortingRepository<Customer, Integer> {
// Pagination and sorting capabilities available
}- JpaRepository
When using Java Persistence API (JPA), which is common in real-world apps, you can extendJpaRepository. This interface adds methods specific to the JPA standard, like batch operations. Batch operations allow you to save multipleCustomerentities at the same time, which can improve performance.
Example: ExtendingJpaRepositoryfor JPA-specific functionality
public interface CustomerRepository extends JpaRepository<Customer, Integer> {
// JPA-specific methods like findAll with sorting
}Each interface in Spring Data builds on the basic functionality. You can choose one based on your needs. Use CrudRepository for simple CRUD operations. For more advanced features, consider PagingAndSortingRepository or JpaRepository.
Using Spring Data Repositories in Your App
With Spring Data, there is no need to manually implement methods such as save() or findById(). When you extend one of the Spring Data interfaces mentioned earlier, Spring Data automatically provides an implementation for you. You simply need to use dependency injection to access this implementation.
Example: Using Spring Data to Manage Customers
To modify our previous JdbcTemplate setup, we can redefine our repository to leverage Spring Data.
1. Add the Spring Data JPA Dependency: Before we can extend JpaRepository, we need to swap out the Spring JDBC dependency with the Spring Data JPA dependency in your pom.xml:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>Make sure to remove the spring-boot-starter-jdbc dependency if it’s still in your file.
2. Update the Customer Entity: Define the Customer entity, which represents the customer table in the database:
@Entity
public class Customer {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private int id;
private String firstName;
private String lastName;
private String email;
// Constructors, getters, and setters
}The @Entity annotation indicates that this class is a JPA entity. The @Id annotation marks the id field as the primary key. @GeneratedValue(strategy = GenerationType.IDENTITY) means the database will automatically generate the ID. These annotations are specific to JPA, which is necessary for managing database interactions, unlike the previous JdbcTemplate setup.
Spring Boot Starter Data JPA creates a table for the JPA entity by default when using H2, resetting every time the application starts.
3. Define the Customer Repository: Create the CustomerRepository interface to handle CRUD operations automatically:
public interface CustomerRepository extends JpaRepository<Customer, Integer> {
// No additional methods needed for basic CRUD operations
}4. Update the Customer Service: Our CustomerService can utilize this repository without needing to explicitly define SQL queries:
@Service
public class CustomerService {
@Autowired
private CustomerRepository customerRepository;
public Customer getCustomerById(int id) {
return customerRepository.findById(id).orElse(null);
}
public String addCustomer(Customer customer) {
customerRepository.save(customer);
return "Customer added successfully";
}
public String updateCustomer(int id, String newEmail) {
Customer customer = getCustomerById(id);
if (customer != null) {
customer.setEmail(newEmail);
customerRepository.save(customer);
return "Customer updated successfully";
}
return "Customer not found";
}
public String deleteCustomer(int id) {
customerRepository.deleteById(id);
return "Customer deleted successfully";
}
}In this revised setup, you’ll notice that most of the boilerplate code has been removed, and data operations are simplified. Spring Data handles the intricacies of connecting to the database and executing queries, allowing you to focus on higher-level business logic. If you want to test the changes, you can use the H2 console again as mentioned earlier.
Conclusion
Spring Data repositories significantly simplify database interactions in your Spring Boot applications. By reducing repetitive code and providing a consistent approach to data access, Spring Data enables developers to build robust applications more efficiently. Combined with JdbcTemplate, you have powerful tools at your disposal to enhance database management in your applications.